 Strojové učení: Data v akci!
Strojové učení: Data v akci!
 Strojové učení: Data v akci!
Strojové učení: Data v akci!
Přijďte se podívat na naše projektů a užít si setkání všech účastníků klubů STEAM Slam 2026.
„Naučila jsem se mnohem víc, než jsem očekávala. A hlavně jsem zjistila, že mě programování baví a chci ho jít studovat na VUT.“
„Všechno, co jsme v klubu o strojovém učení dělali, využiju při tvorbě aplikace v rámci SOČ.“
Co se dělo na setkáních:
20.11.2025 Data v akci - studentské projekty
Nasadili jsme rozhodovací stromy i další nástroje strojového učení a vytvořili vlastní predikční modely — od tržeb kavárny podle počasí až po odhad času úkolu či pořadí jezdců F1 v příštím závodě.

13. 11. 2025 AI kolem nás – chytré aplikace
Jak doporučovací systémy poznají, co se lidem líbí? Podle podobných uživatelů, nebo podle vlastností položek?
Jak lze kombinovat oba přístupy a zároveň zohlednit trendy či kvalitu doporučení?
Kde se může systém mýlit – například u nových uživatelů, populárních trendů nebo zkreslených dat?
Zkoumali jsme také počítačové vidění:
Který obrázek fotil člověk mobilem a který je vytvořený AI modelem Le Chat?


Jak modely vidí obrázky jako matice čísel (pixely) a učí se z nich rozpoznávat vzory pomocí konvolučních neuronových sítí (CNN).
Praktická ukázka: vizualizace váh neuronů, které reagují na různé tvary, linie nebo části obrázku.
Diskutovali jsme, proč a kdy se modely mohou mýlit – například při odlišném osvětlení, překrytí objektů nebo kvůli biasu v datech.
6. 11. 2025 Pokročilejší algoritmy - když jeden strom nestačí
Seznámili jsme se s ensemble metodami, zejména Random Forest, a porovnávali jeho přesnost s klasickým rozhodovacím stromem.
Vyzkoušeli Support Vector Machines (SVM) a vizualizovali rozhodovací hranice pro různé typy jader.
Objevili princip nesupervizovaného učení pomocí K-means clusteringu, naučili se volit optimální počet skupin a poznali jeho limity.
V závěrečném úkolu samostatně analyzovali neznámý dataset, volili vhodný model a vyhodnocovali výsledky.



23. 10. 2025 Jak učit modely chytře – generalizace, data a bias
Proč může AI selhat?
Například model, který rozpoznává tváře, se naučil spolehlivě rozpoznávat muže, ale ženy často přehlíží, protože měl ve tréninku převahu mužských obličejů.
Hlavní cíl:
Zajistit fungování modelu i na nových datech a minimalizovat předpojatost.

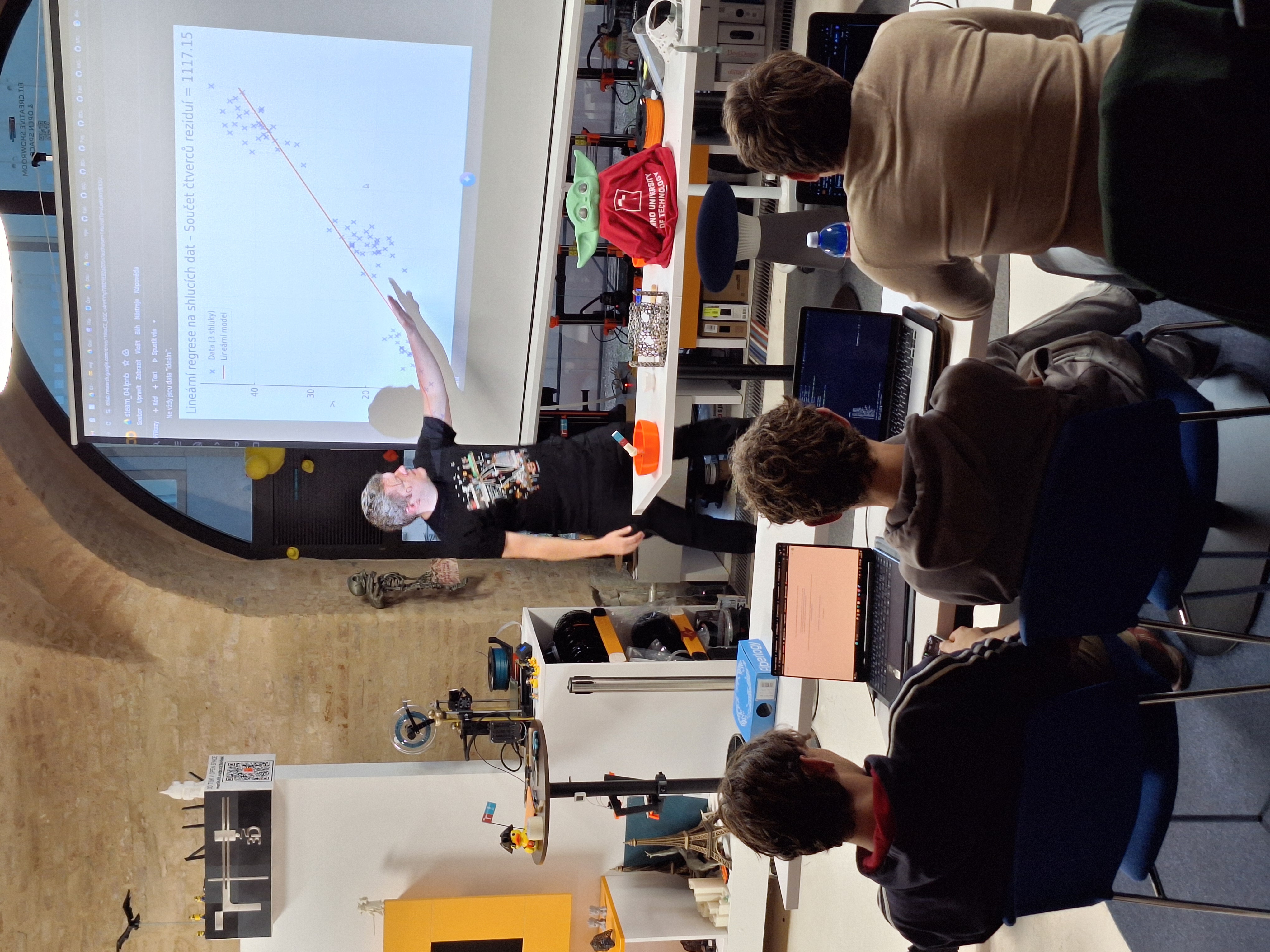
15. 10 2025 Lineární regrese
Vyzkoušeli, jak počítač dokáže „odhadnout“ číslo na základě dat z minulosti. Ukázali jsme si to na příkladu cen domů – zadali jsme údaje jako velikost bytu, příjem lidí v oblasti nebo polohu na mapě a počítač se pomocí tzv. regrese naučil najít vzorec, podle kterého cenu předpovídá.
Co jsme dělali prakticky:
zkoušeli jsme, jak model „kreslí“ nejlepší možnou přímku mezi body v grafu,
počítali jsme, jak moc se jeho odhad liší od skutečnosti,
porovnávali jsme různé vstupní proměnné (např. jen plocha vs. více faktorů),
pracovali jsme s reálným datasetem z Kalifornie.
Co jsme si odnesli:
Čím víc relevantních údajů model má, tím lépe dokáže předpovídat.
Každý model se trochu mýlí — důležité je znát, jak moc.
I jednoduché matematické nástroje mohou být silným pomocníkem při rozhodování.


1. 10. 2025 Klasifikace - rozpoznávání kategorií
Jde o metodu strojového učení, která umí rozpoznávat kategorie a rozhodovat, do které třídy nový objekt patří. 'Odpovídá na otázky typu ano/ne nebo která z možností platí. S klasifikací se setkáváme každý den – při filtrování spamu v e-mailech, doporučování filmů nebo třeba v medicínské diagnostice.
Tréninkový příklad: známý dataset o pasažérech Titanicu. Na základě údajů o věku, pohlaví a lodní třídě jsme odhadovali, zda cestující přežil. Vytvořili jsme první klasifikační model pomocí rozhodovacího stromu: ptá se na jednoduché otázky („Je cestující žena?“ „Byl ve 3. třídě?“) a na jejich základě rozhoduje. Model dosáhl přesnosti kolem 75 %.
Zjištění: samotná přesnost (accuracy) nestačí – model může být nepřesný v menších, ale důležitých skupinách. Proto jsme se naučili používat další nástroje: Confusion matrix, Precision a recall, Precision-recall křivku.
Kromě rozhodovacích stromů jsme vyzkoušeli i další algoritmy: Logistická regrese, KNN a Naivní Bayes.
Na jiných datech (např. slavném Iris datasetu) jsme porovnali výsledky jednotlivých modelů a viděli, že univerzálně nejlepší algoritmus neexistuje. Každý má jiné silné a slabé stránky.
Úkol: vytvořit vlastní klasifikační model – například s využitím dat o tučňácích nebo víně. Zkusili jsme tak nejen práci s různými algoritmy, ale i ladění parametrů a porovnávání výsledků.
Co jsme si odnesli:



25. 9. 2025 Seznámení s datasety – co jsou, typy dat a jejich význam ve strojovém učení.
Práce s konkrétními datasety – Titanic (cestující), Iris (kosatce), MNIST (ručně psané číslice); zkoumání atributů a základní analýza.
Programování v Pythonu/Colab – otevírání datasetů, zjišťování počtu řádků/sloupců, chybějících hodnot a popisné statistiky.
Vizualizace dat – histogramy, countploty, scatterploty, boxploty; objevování souvislostí mezi proměnnými např. graf ukázal, že ženy na Titanicu měly vyšší šanci na přežití než muži! Tedy souvistlost: vliv třídy, pohlaví a cena lístku na přežití.
Samostatné úkoly a kreativní práce – tvorba vlastních grafů, analýza dalších datasetů.
Závěr – data nejsou jen čísla, vizualizace odhaluje důležité souvislosti a pomáhá při predikcích.



18. 9. 2025 Co si představíš pod pojmem Strojové učení?
Na prvním setkání jsme se seznámili s projekty FIT VUT, jako jsou BEEON, 3D mapování, ARTABLE nebo aplikace SUPER LECTURES. Diskutovali jsme i o tématech z praxe – například jak funguje DDoS kybernetický útok, jak využít LiDAR ke skenování vnitřních prostor nebo jak se strojové učení uplatňuje v řečových technologiích – od detekce jazyka, přes přepis komunikace až po hledání hlasu konkrétní osoby. Zmínili jsme i firmu Phonexia s. r.o. , která řečové technologie vyvíjí pro call centra. Nechyběla ani praktická část věnovaná programování robotů. Dozvěděli se také, co je to neurální síť – model, který pomocí nastavení vah rozhoduje, co je nejblíže hledanému výsledku.
chytrou databázi a program, který se učí z daných dat,
nástroj pro rozpoznávání vzorů, posloupností a šablon v datech,
součást umělé inteligence zaměřenou na hledání podobností a vzorců.
Kde vidíme možnosti, kde lze ML využít?
doporučování hudby na Spotify,
detekce srdečních chorob z EKG,
rozpoznávání stylu psaní,
analýza dopravních situací a další.
Potom jsme si vyzkoušeli, co je to model a jeho parametry, které je potřeba najít, aby dobře popisovala měřená data.
Ŕeč byla také o:

